新しい化合物の分子表現法 SELFIESの日本語解説
20210817追記
公式レポジトリに、この記事のリンクが貼られました。
以前日本語で書いたSELFIESの紹介記事リンクが公式レポジトリに貼られた!!😎
— くろたんく@激しく多忙 (@black_tank_top) 2021年8月16日
I woke up in the morning and saw that the link to my Japanese article about SELFIES was added on the README of the official #SELFIES repository!https://t.co/l0fUzGATRb pic.twitter.com/5tNl3b9v8n
はじめに
本記事は、こちらの論文で発表された新たな分子表現であるSELFIESの紹介です。Chemical VAE を作ったことで有名な Aspuru-Guzik 教授のラボで開発されたものです。(arXivには2019年にupされています)
原題: Self-referencing embedded strings (SELFIES): A 100% robust molecular string representation
著者: Mario Krenn, Florian Häse, AkshatKumar Nigam, Pascal Friederich, Alan Aspuru-Guzik
論文誌: Machine Learning: Science and Technology
Publish: 28 October 2020
doi: 10.1088/2632-2153/aba947
論文だけでなく、コードを動かして見た動作や実装された内容から理解して、簡潔さ・伝わりやすさを重視して記述しているので、ご興味を持たれた方は論文や実装を参照してください。
また、今回は最新バージョンのv1.0.4における内容とします。
注意 論文発表後にも開発がかなり進んでいるので論文での記述とv1.0.4におけるアウトプットに若干の乖離があるため、本記事と内容が合ってなくて??となるかもしれません(というか私はそこでハマりました・・・。)
経緯
SELFIESの詳しい文法の日本語解説がどこにも見当たらなかったのと自分の研究に使いたかったので理解を深めたかったという理由もあり、自分で解説を書こうかなと思っていたら、First authorのMario Krennさんからコンタクトがあって、ブログでSELFIESについて書いていいという流れになりました。そこから少し論文を読み直し、現状のバージョンのSELFIESとの挙動の差を検討して、文法をほぼ完全に理解したので解説します。
論文概要
化合物を表す標準的な文字列分子表現として多く使われているのはSMILESですが、生成モデルの入出力にSMILES使うとかなりの部分が有効な分子に対応していないという問題があります。原因としては、生成された文字列が構文的に無効であったり、原子間の最大価結合数などの基本的な化学ルールに違反していたりします。このような問題を解決するために著者らはSELFIESを開発したようです。
全くランダムなSELFIESの文字列でも、正しい分子グラフを表現することができます。これを実現するために、著者らは理論計算機科学のアイデア、すなわちformal grammar とformal automatons(formal Chomsky type-2 grammar (or analogously, a finite state automata))を利用してSELFIESを開発しました。
論文上では、SELFIESとSMILESを用いてVAEやGANを試した結果,SMILESを用いた場合よりもSELFIESを用いた場合の方が,出力は完全に有効であり,モデルは桁違いに多様な分子を生成出来ることが示されています。(Table 1, Figure 5, Figure 6)
(個人的に思う)SELFIESのすごいところ
- SELFIESは、RingとBranchの始まりと終わりを文字列で示す代わりに、環と枝をその長さで表す。RingとBranchの記号の後に続く記号を長さを表す数字として解釈することで、構文上の問題を回避(後ほどでてくるIndex Symbolsのこと)
- 価数を考慮して符号化される。
- C=C=Cは可能(3つの炭素が二重結合でつながっている)だが、F=O=Fは不可能(Fは1つの結合、Oは2つの結合までしか不可能)という物理的制約を確実に満たす様に設計されている。
- 自分自身でもグラフニューラルネットワークを使って、Mol to SELFIES, Mol to SMILESのVAEを試しているがSMILESもSELFIESも生成自体はうまくいくが、SMILESだと殆どがValid(数%)にならないが、SELFIESだと100%Validになっている。(試した結果の詳細は別の機会に)
その他SELFIESを用いた成果
上記論文の結果から、SELFIESは深層生成モデルや遺伝的アルゴリズムに基づく機能性分子の逆設計タスクにおいて、優れた動作をもたらすと考えられます。すでに、SELFIESを用いて続々と成果が出ています。
・遺伝的アルゴリズムを用いた inverse design
・分子画像からSMILESへの変換
・SMILESからIUPAC-name への変換
SELFIESの文法の解説(本題)
SMILESについて
そもそもSMILESについてわかってないとこの記事自体、全然意味分かんないんだけど、SMILESについてはある程度わかっている前提で書きます。
SMILESってなんやねんっていう人はまずは、py4chemoinformaticsを読んで、RDKitの使い方も含めてドメイン知識を溜めるとよいかと思います。
また、金子先生の本を読んで化学データの解析とそれらを用いた機械学習を一通り学ぶのも良いかもしれません。

SMILESを含んだその他の分子表現について
こちらは、@steroidinlondonさんが簡単に説明していくれているのでこちらを一読されるとよいかと思います。
MDMA解説(とりあえず眺めるだけ)
さて、解説を始めていきます。
まず、論文のFigure 1にも出てくるMDMA(3,4-Methylenedioxymethamphetamine)のSMILESが書いてあるのでそれをそのまま、Colabを使って、RDKitでChem.MolFromSmiles("CNC(C)CC1=CC=C2C(=C1)OCO2")すると以下のように描画されます。

つまり、MDMAのSMILESはCNC(C)CC1=CC=C2C(=C1)OCO2ということですね。
一方で、MDMAのSELFIESはどうなるのでしょうか?
import selfies as sf sf.encoder("CNC(C)CC1=CC=C2C(=C1)OCO2") # [C][N][C][Branch1_1][C][C][C][C][=C][C][=C][C][Branch1_2][Ring2][=C][Ring1][Branch1_2][O][C][O][Ring1][Branch1_2]
この時点で、論文のSELFIESの表現のと違うので一旦、論文は閉じましょう(結果同じことだと言うのはわかります(当時のバージョンではこういう表現だったというだけ))。
ちゃんとFigure 2を読めばわかるのかもしれないが、とりあえずパっと見意味がわからない。まず"C"の数が元のSMILESより増えている様に見えます。いきなりMDMAで理解しようとするときついので、もっと簡単な例でいきます。
SELFIESの文法を理解するには、Atomic Symbols, Index Symbols, Branch Symbols, Ring Symbolsを理解する必要があります。ここがきちんとおさえられれば多分問題ないはずです。
Atomic Symbols
まずは適当な例を示します。
sf.encoder("C=CC#C[13C]") # [C][=C][C][#C][13Cexpl] sf.encoder("CF") # [C][F] sf.encoder("COC=O") # [C][O][C][=O]
Atomic Symbolsは、結合種類を表すbond typeと、SMILESで表されるatom typeで構成されて[
bond typeはSMILESと同じで、
- 単結合なら ''(何もなし)
- 二重結合なら '='
- 三重結合なら '#'
- 幾何異性は '/', '\\'で
表現されます。
Atom typeはSMILESと同じです。ただ、[13C]とか[C@@H]みたいに明示的にカギカッコ([])した場合はexplという文字が付加されます。ちなみにイオンも可能です。
SELFIESのValidityが高いことの一つの理由はDecoderにあると考えています。例を見てみましょう。
# 上と同じものを再掲 sf.encoder("COC=O") # [C][O][C][=O] sf.decoder("[C][O][C][=O]") # COC=O # 価数を無視して適当な化合物を書いても可能な部分までしかデコードされない sf.decoder("[C][O][=C][#O][C][F]") # COC=O
この様に前の原子や現在の原子の結合制約に違反する場合は、すべての結合制約が満たされるように、結合多重度が(最小限に)減少するように設計されています。 (このあたりに価数を与えている記述があります。XXXXX_bond_constraints)
ここまでで、単純に直鎖の場合は理解できると思います。 次に、Branch SymbolsとRing Symbolsについて説明しようと思いますが、その前に先程のMDMAの説明中に"C"が増えてる様に見えると言う話がありますがそれは、Branch SymbolsとRing Symbolsの説明に必須のIndex Symbolsについて先に説明する必要があります。
Index Symbols
個人的にとてもハマったところ(気づけなかったところ)だったのですが、前述していますが以下がポイントです。
SELFIESは、RingとBranchの始まりと終わりを文字列で示す代わりに、環と枝をその長さで表す。
RingとBranchの記号の後に続く記号を長さを表す数字として解釈する。
これはどういうことかというと、原子、分岐構造、環状構造を表す文字列をindexと考えるということです。
このあたりに記述があります。
表で示すと以下の通りです。
| Index | Symbols |
|---|---|
| 0 | [C] |
| 1 | [Ring1] |
| 2 | [Ring2] |
| 3 | [Branch1_1] |
| 4 | [Branch1_2] |
| 5 | [Branch1_3] |
| 6 | [Branch2_1] |
| 7 | [Branch2_2] |
| 8 | [Branch2_3] |
| 9 | [O] |
| 10 | [N] |
| 11 | [=N] |
| 12 | [=C] |
| 13 | [#C] |
| 14 | [S] |
| 15 | [P] |
論文上で𝑄 という言葉が多用されますが、これはこのことです。 16進数で考えて、𝑄を 𝑄 = (idx(𝑠1)×162)+(idx(𝑠2)×16)+idx(𝑠3) という式にで表現します。
どういうことかというと例を見たほうが早いのでBranch Symbolsの例を見ましょう。
Branch Symbols
というわけで、Index Symbolsで𝑄の計算ができるようになったので、分岐構造がある例を見てみましょう。
# SO4 sf.encoder("S(=O)(=O)([O-])[O-]") # [S][Branch1_2][C][=O][Branch1_2][C][=O][Branch1_1][C][O-expl][O-expl]
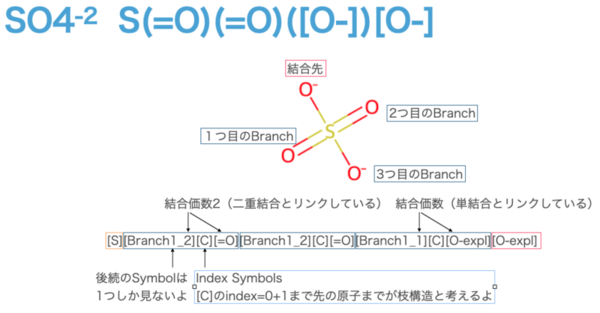
まず、Branch Symbolsは、[Branch{L}_{M}]のパターンがあります。左側のLは{1, 2, 3}が範囲で数字は、後続する何文字目までをIndex Symbolsとして見るかという意味です。1であれば1文字、2であれば2文字ですね。この例では2文字目まで見ているものはありません。2文字目まで見る場合というのは、たとえば"C"が17文字以上続くような、長い鎖を想定する必要があります(のちほほど紹介する)。
次に、[Branch{L}_{M}]の右側のMは{1, 2, 3}が範囲です。これは、Index Symbolsのあとの原子との結合パターンを示しています。単結合なら1, 二重結合なら2, 三重結合なら3といった具合です。もちろん、その対象のAtom Symbolはリンクしています。ちなみにどちらか一方を満たさない場合は、前の原子や現在の原子の結合制約に違反する場合は、すべての結合制約が満たされるように、結合多重度が(最小限に)減少するように設計されているので、少ないほうが優先されます。
SO4を例に[Branch1_2]の場合を場合を考えると、後続のIndex Symbolsは1文字しか見ないので、[C]だけがIndex Symbolsとして処理されます。ちなみに先程示した表で[C]はindexが0です。ここで注意したいのは、分岐構造がどこまで続くのかをIndex Symbolsから計算した𝑄で考えますが、𝑄+1 コのSymbolまで分枝構造として考えます。この場合すべて[C]なので後続の1文字目までが分岐構造です([=O] or [O-expl])
Branch Symbolsがなくなったものが、直結しているものと考えるとわかりやすいです。(今回の例だと頭とお尻が直結していて、その他3つが分岐構造のように考える)
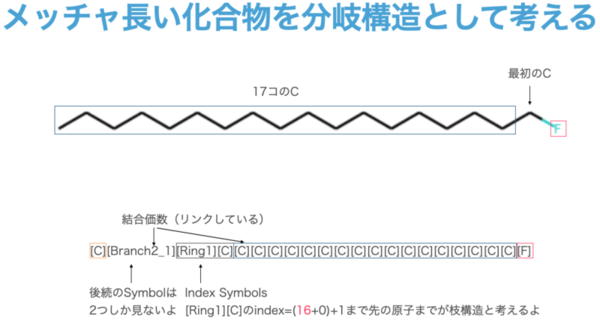
ちなみに[Branch2_1]のようになるような例は以下の様なケースで、まぁ滅多なことでは登場しないでしょうが、このような長鎖であっても原理上は可能であるということです。(Branch3まで可能なので16 ** 3 というとても長いものが可能です)
Ring Symbols
さて、ここまで分かればRing Symbolsはとても簡単です。
Ring Symbolsは、大きく2つのパターンがあり、[Ring
まあ、例を見ましょう。みんな大好き(??)ベンゼン環がわかりやすいですね。
sf.encoder("C1=CC=CC=C1") # [C][=C][C][=C][C][=C][Ring1][Branch1_2] # ↑ ↑ ↑ ↑ ↑ ↑ # 5 4 3 2 1 基準
ここで注意したいのは、[Ring1]のあとはIndex Symbolsです。[Branch1_2]と出ていますがこれはただのindexと考えるものです。[Ring1]なのでIndex Symbolsとして考えるのは後続の1文字だけです。[Branch1_2]はIndex Symbolsの表で見ると𝑄 = 4なので、𝑄+1番目前つまり5コ前のAtomic Symbolsは、一番最初の[C]ですね。これと結合して環構造を作ります。
また、[ExplC=1C=CC=CC=1と書くこともできます。こちらをSELFIESにすると以下のようになります。
sf.encoder("C=1C=CC=CC=1") # [C][C][=C][C][=C][C][Expl=Ring1][Branch1_2] # ↑ ↑ ↑ ↑ ↑ ↑ # 5 4 3 2 1 基準
基本は同じですが、[Expl=Ring1]となっているので、Ring Symbolsの直前の基準のAtomic Symbolsと環構造を作るときにbond typeを"="にしてねっていう書き方です。(SMILESの最後の=1と[Expl=Ring1]が対応しているイメージで良いかと思います。)
おまけ
Ring Symbolsは少し面白くて、アセチレンのような3重結合をRing Symbolsで書くこともできます。(要するにすでに単結合がある部分に、二重結合で環構造つくると三重結合になるという仕組みっぽいです)
sf.decoder("[C][C][Expl=Ring1][C]") # C#C
MDMA解説
ここまで来ると、先に示したMDMAが完全に理解できます。
import selfies as sf sf.encoder("CNC(C)CC1=CC=C2C(=C1)OCO2") # [C][N][C][Branch1_1][C][C][C][C][=C][C][=C][C][Branch1_2][Ring2][=C][Ring1][Branch1_2][O][C][O][Ring1][Branch1_2]

いい感じに色分けができなかったので少し分かりづらいですが、これまでの前提を総動員すると問題なく理解できます。
難しいところは真ん中らへんの[Branch1_2][Ring2][=C][Ring1][Branch1_2]このあたりで、分岐構造の先を環構造で
つなげるていう状態になっていてまぁ結構むずいですが、すこーし真剣に考えると理解できるかと思います。
Colab
今回、思考錯誤出来るように手元で実行したかったのでColabで行っていました。閲覧出来るようになっているので、多分自分なりに変更するなりダウンロードして試すなり色々出来ると思います。
まとめ
これで、SELFIESの文法についてはほぼ完全に理解が深まったかと思います。
では何故この形式で記述されたSELFIESはSMILESと異なり、VAE・GANなどの生成モデルに有効的に働くのでしょうか?若干理解が追いついてない部分もあるかもしれないので、私が勝手に思っていることですが、やはり、SELFIESはランダムに並び替えても、100%Validな化合物を表し、超ロバストであり、結果として、潜在空間内に無効な領域が無いことが非常に重要だと考えています。
自分の研究にもうまく使えないかなぁと考えています。
終わりに
自分の理解した複雑な内容のものを、わかりやすく説明する説明するというのはいつになっても難しいと感じますね。
おそらく、日本語でここまで丁寧にSELFIESに関して説明したものは無いと思います。結果として10000字を超えるような記事になってしまいましたが、自分の周りでも利用者が増えて、実用場面でのPros and Consなどディスカッションする機会などが増えると良いなと考えています。
また記事はかなり即興で書いたこともあり、間違いがあるかもしれません。発見された方は、ご指摘していただけるとありがたいです。
参考
@steroidinlondonさんの ご注文はリード化合物ですか?〜医薬化学録にわ〜
本家GitHubページ github.com
extensive blog post aspuru.substack.com
公式Document selfies.readthedocs.io